FPGA может быть использована для решения нескольких задач, требующих больших вычислений. опираясь на конвейерную параллельную архитектуру, FPGA имеет технические преимущества по сравнению с GPU и CPU в обратной задержке результатов вычислений.
задачи, требующие больших вычислений: матричные операции, машинное зрение, обработка изображений, сортировка поисковых систем, асимметричное шифрование и другие виды операций являются задачами, требующими больших вычислений. эта операционная задача может быть выгружена на FPGA с помощью CPU.

производительность FPGA при выполнении вычислительных задач:
производительность вычислений относительно процессора: например, FPGA серии Stratix выполняет целочисленное умножение, его производительность эквивалентна производительности 20-ядерного процессора, а производительность умножения с плавающей запятой эквивалентна производительности 8-ядерного процессора.
производительность вычислений сравнивается с GPU: FPGA для целочисленного умножения и умножения с плавающей запятой, и существует разница на порядок между производительностью и GPU. она может быть близка к производительности GPU, настраивая множители и вычислительные единицы с плавающей запятой.
основное преимущество FPGA в реализации задач, требующих больших вычислений: сортировка поисковых систем, обработка изображений и другие задачи требуют строгих временных ограничений для возврата результатов, и необходимо сократить задержку на этапе вычислений. при традиционной схеме ускорения GPU размер пакета велик, и задержка может достигать уровня миллисекунд. в соответствии со схемой ускорения FPGA задержка PCIe может быть уменьшена до микросекунд. с помощью технологии Forward задержка передачи данных CPU и FPGA может быть снижена до менее чем 100 наносекунд.
FPGA может построить равное количество трубопроводов (параллельная структура трубопровода) в зависимости от количества шагов пакетов, и пакеты могут быть выведены сразу после обработки несколькими трубопроводами. параллельный режим данных GPU опирается на различные единицы данных для обработки различных пакетов данных, и единицы данных нуждаются в последовательном вводе и выходе. для потоковых вычислений конвейерная параллельная архитектура FPGA имеет естественное преимущество с точки зрения латентности.
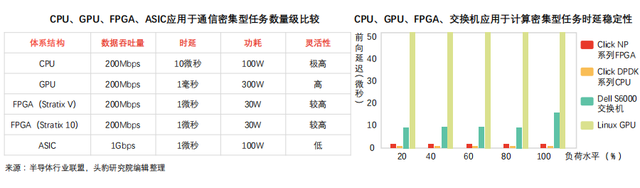
когда FPGA используется для решения задач, связанных с коммуникацией, она не ограничивается сетевой картой и лучше, чем CPU, с точки зрения пропускной способности и задержки пакетов, и имеет сильную стабильность задержек.
Коммуникационно-емкие задачи: симметричное шифрование, брандмауэр, сетевая виртуализация и другие операции относятся к коммуникационно-интенсивным вычислительным задачам. по сравнению с вычислительной обработкой, коммуникационно-интенсивная обработка данных имеет более низкую сложность и легко ограничена коммуникационными аппаратными устройствами.


FPGA выполняет задачи, связанные с коммуникацией:
1преимущество пропускной способности: схема процессора для решения задач, связанных с коммуникацией, должна получать данные через сетевую карту, что легко ограничено производительностью сетевой карты (сетевая карта обработки байтовых пакетов ограничена, количество слотов PCIe и материнской платы PCIe ограничено). схема GPU (высокая производительность вычислений), чтобы справиться с коммуникационно-емкими пакетами задач, отсутствие сетевого порта, необходимость полагаться на сетевую карту для сбора пакетов данных, пропускная способность данных ограничена процессором и сетевой картой, и задержка длительна. FPGA может получить доступ к сетевым линиям 40 Гбит / с и 100 Гбит / с, а также обрабатывать все виды пакетов данных со скоростью проволоки, что может снизить стоимость конфигурации сетевой карты и коммутатора.
2преимущество задержки: схема CPU собирает пакеты данных через сетевую карту и отправляет результаты расчета на сетевую карту. ограниченная производительностью сетевой карты, в рамках обработки пакетов DPDK задержка процессора в решении задач, связанных с коммуникацией, составляет почти 5 микросекунд, а стабильность задержки процессора слаба. при высокой нагрузке задержка может превышать десятки микросекунд, что приводит к неопределенности в планировании задач. FPGA не нуждается в инструкциях и может обеспечить стабильность и очень низкую задержку. FPGA в сотрудничестве с CPU гетерогенным режимом может расширить применение схемы FPGA в сложных устройствах.
развертывание FPGA включает кластеризацию, распределение и так далее, а также постепенный переход от централизации к распределению. при различных режимах развертывания эффективность серверной связи и эффект проводимости неисправностей различны.
встроенная нагрузка на питание FPGA: вложение FPGA мало влияет на общее энергопотребление сервера. возьмем в качестве примера проект FPGA по ускоренному машинному переводу, осуществляемый катапультой и Microsoft, общая вычислительная мощность модуля ускорения достигает 103Tops / W, что эквивалентно 100000 GPU. относительно говоря, вложение одной FPGA увеличивает общее энергопотребление сервера примерно на 30 Вт.
особенности и ограничения развертывания FPGA:
1характеристики и ограничения развертывания кластеров: чипы FPGA образуют выделенный кластер и образуют суперкалькулятор, состоящий из ускорительных карт FPGA (например, ранние экспериментальные платы серии Virtex развертывают 6 FPGA на том же кремниевом чипе, а 4 экспериментальные платы переносятся на юнит-сервер).
выделенный режим кластера не может взаимодействовать между различными машинами FPGA
другие машины в центре обработки данных должны отправлять задачи в кластер FPGA централизованно, что может легко вызвать задержки в сети.
одна точка отказа ограничивает общую пропускную способность центра обработки данных



